异构计算的发展
什么是“异构计算”
随着人工智能、大数据等概念的兴起,异构计算已经是半导体行业、IT行业的热门词汇。异构计算(Heterogeneous Computing),主要指不同类型的指令集和体系架构的计算单元组成的系统的计算方式。
对于业内人士来说,"异构"并不算什么新词汇。我在HW公司做嵌入式X86电路的时候,就在这个方面做出过很多的构想和分析:例如,FPGA实现QPI、HT的高速总线与X86进行对接;FPGA不只是实现一些Glue Logic,是不是有一天,Intel会开放出南桥,即后来的PCH,由客户自定义接口,或者用FPGA来替代南桥,自定义接口和硬件加速模块。
其实在这更早,20世纪80年代,异构计算技术就已经诞生了。所谓的异构,就是CPU、DSP、GPU、ASIC、协处理器、FPGA等各种计算单元、使用不同的类型指令集、不同的体系架构的计算单元,组成一个混合的系统,执行计算的特殊方式,就叫做“异构计算”。
为什么需要异构计算
原因很简单:我们需要越来越强大、越来越高效的计算系统。在过去,随着半导体技术的进步和频率的提升,绝大多数计算机并不需要结构性的变化,或者特定的硬件加速,即可不断提升性能,但是现代应用经常会碰到内存、功耗方面的限制,导致计算力的瓶颈。引入特定的单元让计算系统变成混合结构成为了必然,每一种不同类型的计算单元都可以执行自己最山擅长的任务。
CPU虽然运算不行,但是擅长管理和调度,比如读取数据,管理文件,人机交互等,例程多,辅助工具也很多。
DSP相比而言管理弱了,运算加强了。这两者都是靠高主频来解决运算量的问题,适合有大量递归操作以及不便拆分的算法。
GPU管理更弱,运算更强,但由于是多进程并发,更适合整块数据进行流处理的算法
FPGA能管理能运算,但是开发周期长,复杂算法开发难度大。适合流处理算法,不管是整块数据进还是一个一个进。还有实时性来说,FPGA是最高的。前3种处理器为了避免将运算能力浪费在数据搬运上,一般要求累计一定量数据后才开始计算,产生群延时,而FPGA所有操作都并行,因此群延时可以很小。
当人工智能等海量计算力诉求到来之后,GPU、FPGA去配合CPU进行计算的使命就自然而然的产生了。
虽然CPU主频最高,但是单颗也就8核,16核的样子,一个核3.5G,16核也就56G,再考虑指令周期,每秒最多也就30G次乘法。还是定点的。
DSP虽然主频不如cpu,但是胜在乘法器多,随随便便带16个乘法器,还是浮点的。再来个4核,8核,还有特定的算法硬件加速,所以虽然主频只有1,2g但是运算能力还是比cpu强。当然现在出现了带专用乘法器的CPU,DSP也集了ARM核,这两个的界限开始模糊了。
GPU的主频一般在500MHz左右,但是核多啊,比如titan,有380多个流处理单元,500*400就是200G这个量级,远大与于前面2者了。
FPGA的运算能力的,拿高端的来说。,3000多个固定乘法器,拿数字逻辑还能搭3000个,最快能到接近300MHz, 也就是1800G这个量级。
GPU+CPU暂时领先
对于普通用户来说,最熟悉的异构计算平台就是“CPU+GPU”的架构。这是PC机上最常见的组合,这也是得益于这些年来,各家显卡厂家、处理器厂家的军备竞赛。以英伟达、AMD为代表的GPU厂家大肆宣传GPU极大加速通用计算。各个GPU厂家都推出了适用于通用计算的GPU,GPGPU(General Perpose GPU)
在几年前,GPU还只是专门处理图形的专门的服务器或者PC的一个部件。然而通用计算的大门打开之后,GPU被导入高并行计算领域,成为了超级计算机的新核心。
APU是“Accelerated Processing Units”的简称,中文名字叫加速处理器,是AMD融聚未来理念的产品,它第一次将处理器和独显核心做在一个晶片上,协同计算、彼此加速,同时具有高性能处理器和最新支持DX11独立显卡的处理性能,大幅提升电脑运行效率,实现了CPU与GPU真正的融合。
从APU的发展来看,AMD在做的事情是让CPU和GPU彻底融为一体,无论是AMD的Llano,还是Brazos,目标都是一致的。AMD认为,CPU和GPU的融合将分为四步进行:第一步是物理整合过程(Physical Integration),将CPU和GPU集成在同一块硅芯片上,并利用高带宽的内部总线通讯,集成高性能的内存控制器,借助开放的软件系统促成异构计算。第二步称为平台优化(Optimized Platforms),CPU和GPU之间互连接口进一步增强,并且统一进行双向电源管理,GPU也支持高级编程语言。第三步是架构整合(Architectural Integration),实现统一的CPU/GPU寻址空间、GPU使用可分页系统内存、GPU硬件可调度、CPU/GPU/APU内存协同一致。第四步是架构和系统整合(Architectural & OS Integration),主要特点包括GPU计算环境切换、GPU图形优先计算、独立显卡的PCI-E协同、任务并行运行实时整合等等。
硬件的异构,需要软件进行统一
OpenCL的诞生为异构计算奠定了坚实的基础。
OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境。借助OpenCL,软件开发人员能够为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
OpenCL最初苹果公司开发,拥有其商标权,并在与AMD,IBM,英特尔和nVIDIA技术团队的合作之下初步完善。随后,苹果将这一草案提交至Khronos Group。
2008年6月的WWDC大会上,苹果提出了OpenCL规范,旨在提供一个通用的开放API,在此基础上开发GPU通用计算软件。随后,Khronos Group宣布成立GPU通用计算开放行业标准工作组,以苹果的提案为基础创立OpenCL行业规范。5个月后的2008年11月18日,该工作组完成了OpenCL 1.0规范的技术细节。2010年6月14日,OpenCL 1.1 发布。2011年11月15日,OpenCL 1.2 发布。2013年11月19日,OpenCL 2.0发布。
OpenCL工作组的成员包括:3Dlabs、AMD、苹果、ARM、Codeplay、爱立信、飞思卡尔、华为、HSA基金会、GraphicRemedy、IBM、Imagination Technologies、Intel、诺基亚、NVIDIA、摩托罗拉、QNX、高通,三星、Seaweed、德州仪器、布里斯托尔大学、瑞典Ume大学。像Intel、NVIDIA和AMD都是这个标准的支持者,不过微软并不在其列。
天底下有事,就有FPGA的事
FPGA作为数字电路的乐高,像幽灵一样存在于各种场景里面。特别是某个行业的初始阶段,例如通信行业的早期,很多私有协议、加密、分发、无线的算法,在没有规模化的时候,实时的充当中流砥柱。
当GPU已经跑在前面的时候,加上OpenCL的到来,欢欣鼓舞。然而FPGA厂家也嗅到了OpenCL带来的新的机会。Altera在2011年11月就悄悄发布了面向FPGA的OpenCL的计划。
FPGA设计思路与CPU、GPU完全不一样。硬件描述语言不同于编程语言。早期有些大公司,甚至转化一些程序员去写Verilog。虽然它是一种语言,但是需要有数字电路的思想和思维方式,所以不适用于市面上海量的程序员的从业人口,所以有时被人称为门槛高。
有了OpenCL解决了这种思维鸿沟,为FPGA加入异构大军助力。
OpenCL应用程序含有两部分。OpenCL主程序是纯软件例程,以标准C/C++编写,可以运行在任何类型的微处理器上。例如,这类处理器可以是FPGA中的嵌入式软核处理器、硬核ARM处理器或者外置x86处理器,如图4所示。
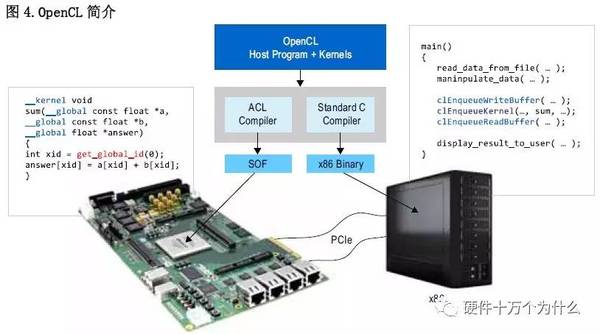
在这一主软件例程执行期间的某一点,某一功能有可能需要很大的计算量,这就可以受益于并行器件的高度并行加速功能,例如CPU、GPU、FPGA等器件。要加速的功能被称为OpenCL内核。采用标准C编写这些内核;但是,采用结构对其进行注释,以设定并行处理操作和存储器等级。图5中的例子对两个数组a和b进行矢量加法,将结果写回输出数组应答中。矢量的每一元素都采用了并行线程,当采用像FPGA这类具有大量精细粒度并行单元的器件进行加速时,能够很快的计算出结果。主程序使用标准OpenCL应用程序接口(API),支持将数据传送至FPGA,调用FPGA内核,传回得到的数据。
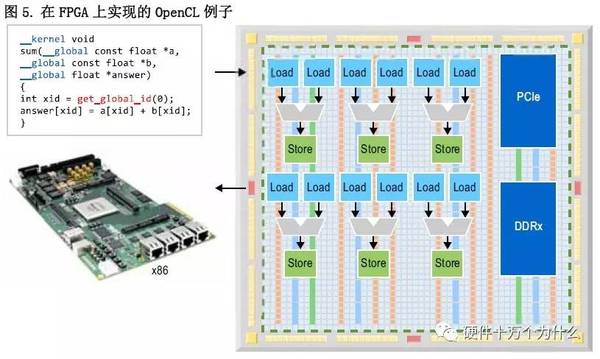
与CPU和GPU不同,其并行线程可以在不同的内核中执行,而FPGA能够提供不同的策略。可以把内核功能传送到专用深度流水线硬件电路中,它使用了流水线并行处理概念,在本质上就是多线程的。这些流水线的每一条都可以复制多次,与一条流水线相比,提供更强的并行处理功能。如图5所示,可以通过级联功能单元实现矢量加法内核,在OpenCL描述中实现每一操作,进行复制以满足实际应用的吞吐量和延时要求。
虽然所显示的只是一个简单表征,但每个功能单元都可以是深度流水线,以保证最终电路的工作频率足够高。此外,编译器可以建立电路来管理与外部系统的通信。在这个例子中,DDRx控制器和PHY连接至内核,使其能够高效访问片外阵列。类似的,PCI Express?(PCIe?)IP自动例化,连接至内核,这样,x86主机能够通过OpenCLAPI与FPGA加速器进行通信。
在FPGA上实现OpenCL标准的优势
使用OpenCL描述来开发FPGA设计,与基于HDL设计的传统方法相比,具有很多优势。最显著的优势如图所示。开发软件可编程器件的流程一般包括进行构思、在C等高级语言中对算法编程,然后使用自动编译器来建立指令流。
这一方法可以与传统基于FPGA的设计方法相比。这里,设计人员的主要工作是对硬件按照每个周期进行描述,用于实现其算法。传统流程涉及到建立数据通路,如图所示,通过状态机来控制这些数据通路,使用系统级工具(例如,SOPCBuilder、PlatformStudio)连接至底层IP内核,由于必须要满足外部接口带来的约束,因此,需要处理时序收敛问题。OpenCL编译器的目的是帮助设计人员自动完成所有这些步骤,使他们能够集中精力定义算法,而不是重点关注乏味的硬件设计。以这种方式进行设计,设计人员很容易移植到新FPGA,性能更好,功能更强,这是因为OpenCL编译器将相同的高级描述转换为流水线,从而发挥了FPGA新器件的优势。
案例:MonteCarloBlack-Scholes方法
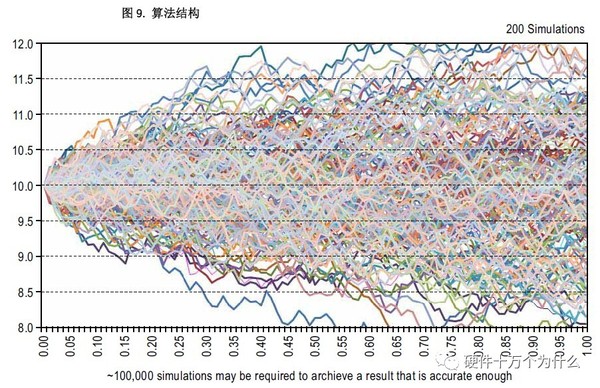
在金融市场上最重要的一个基准测试方法是通过Monte Carlo Black-Scholes方法计算期权价格。该方法基于对底层股票价格的随机仿真,以及数百万不同路径上的平均预期收益。图8以图形化的方式显示了这类仿真的一个例子。
图9显示了进行这一计算的高级算法结构。首先采用Mersenne旋转随机数发生器来创建均匀分布的数值。将随机数序列送入逆正态累积密度函数,以产生正态分布序列。然后,使用几何布朗运动,这些随机数用于仿真股票价格的变化。在每一仿真通路的最后,记录看涨期权的收益,进行平均来产生收益预期值。整个算法通过大约300行的OpenCL代码来实现,可以从FPGA移植到CPU、GPU。
利用针对Altera FPGA开发的OpenCL工作台,可以产生很好的基准测试结果,如表1所示。与相应的GPU相比,面向Stratix? IV FPGA EP4SGX530的OpenCL工作台在吞吐量上超过了CPU和GPU。与相应的GPU相比,在执行相同的代码时,FPGA解决方案不但提高了吞吐量,保守估计,功耗也只有其五分之一。速率和高功效相结合,降低了大计算量应用的功耗需求。
利用FPGA上的OpenCL标准,与目前的硬件体系结构(CPU、GPU,等)相比,能够大幅度提高性能,同时降低了功耗。此外,与使用Verilog或者VHDL等底层硬件描述语言(HDL)的传统FPGA开发方法相比,使用OpenCL标准、基于FPGA的混合系统(CPU+FPGA)具有明显的产品及时面市优势。Altera于2010年加入Khronos集团,为标准建设做出了积极贡献。
最终谁赢?
我们在硬件十万个为什么的前期文章中,也进行过投票。具体谁在人工智能的热潮中,博得胜利,谁也说不好。我个人觉得,FPGA的命运很可能如同其在通信市场中一样,在早期,算法不固定,需求不明确,应用种类纷杂的情况下,先发上场,但是随着算法固定,产业成熟,巨头出现。逐步会被ASIC替代。
目前,各个巨头都在站队:英伟达、AMD、苹果站在GPU这个阵营,Intel收购了Altera站在了FPGA的阵营,谷歌是个冒进的公司,自研了TPU,早早站在了ASIC阵营。
但是正如ARM战胜PowerPC、MIPS一样,最终胜利的一定是那个生态最好的,小伙伴们都愿意跟着他跑的那个阵营。易用性非常的关键。这点上来说,GPU跑得快是有原因的,程序员都喜欢。
逻辑类
可编程逻辑器件概述
可编程逻辑之独孤九剑(1)
可编程逻辑之独孤九剑(2)
FPGA工作原理与简介
FPGA设计方法概论
随机误码模拟方法浅谈
薛定谔猫 与 建立保持时间
为什么会有建立时间(Setup Time)和保持时间(Hold Time)?
亚稳态分析
FPGA工作原理与简介
PLD/FPGA 结构与原理初步
CPLD、FPGA加载原理
门控时钟
如何采用门控时钟来设计低功耗时序电路
FPGA设计方法概论
verilog中阻塞赋值和非阻塞赋值的区别
衍生时钟和门控时钟
用什么加速“深度学习”
深度学习的三种硬件方案:ASIC,FPGA,GPU;你更看好?
硬件工程师是不是越老越吃香?
让ARM穿上FPGA的马甲,会演一出什么好戏?Zynq
FPGA项目的执行需要规范体系,代码规范只是一个组成部分
超级云计算:FPGA的大好机会
-------------广告------------
本期由三豪商学院赞助播出
查看评论 回复