人工智能芯片:发展史、CPU、FPGA和专用集成电路 - 嵌入式处理器
人工智能芯片(一):发展史
人工智能算法的实现需要强大的计算能力支撑,特别是深度学习算法的大规模使用,对计算能力提出了更高的要求。深度学习模型参数多、计算量大、数据的规模更大,在早期使用深度学习算法进行语音识别的模型中,拥有429个神经元的输入层,整个网络拥有156M个参数,训练时间超过75天;人工智能领军人物Andrew Ng和Jeff Dean打造的Google Brain项目,使用包含16000个CPU核的并行计算平台,训练超过10亿个神经元的深度神经网络。下一步,如果模拟人类大脑的神经系统,需要模拟1000亿个神经元,计算能力将有数个量级的提升。
除此之外,随着以智能手机为代表的移动终端快速发展,人们也希望将人工智能应用于移动终端,而这对硬件的计算能力和能耗提出了更高的要求。传统实现移动终端人工智能的方法是通过网络把终端数据全部传送到云端,之后在云端计算后再把结果发回移动端,例如苹果的Siri服务。然而,这样的方式会遇到一些问题:第一,使用网络传输数据会产生延迟,很可能数据计算的结果会需要等待数秒甚至数十秒才能传回终端。这样一来,那些需要立刻得到计算结果的应用就不能用这种方式。例如无人机上使用的深度学习躲避障碍物算法,ADAS系统中使用的图像识别算法等,如果计算过程不是本地进行而是依赖云端,那么云端和终端的通讯延迟、可靠性等问题有可能对汽车和无人机造成非常严重的后果。第二,一旦使用网络传送数据,那么数据就有被劫持的风险。因此,那些要求低计算延迟以及对于数据安全性非常敏感的应用就需要把人工智能算法全部在终端实现,或者至少在终端完成一些预处理运算然后再把少量运算结果(而不是大量的原始数据)传送到云端完成最终计算,这就需要移动终端硬件能够快速完成这些运算。因此,移动端硬件完成这些运算必须同时满足高速度和低功耗的要求。
针对这些需求,人工智能核心计算芯片也经历了四次大的变化。2007年以前,人工智能研究和应用经历了数次起伏,一直没有发展成为成熟的产业;同时受限于当时算法、数据等因素,这一阶段人工智能对于芯片并没有特别强烈的需求,通用的CPU芯片即可提供足够的计算能力。之后,由于高清视频、游戏等行业的发展,GPU产品取得快速的突破;同时人们发现GPU的并行计算特性恰好适应人工智能算法大数据并行计算的要求,如GPU比之前传统的CPU在深度学习算法的运算上可以提高9倍到72倍的效率,因此开始尝试使用GPU进行人工智能的计算。进入2010年后,云计算广泛推广,人工智能的研究人员可以通过云计算借助大量CPU和GPU进行混合运算,事实上今天人工智能主要的计算平台还是云计算。但人工智能业界对于计算能力的要求不断快速地提升,因此进入2015年后,业界开始研发针对人工智能的专用芯片,通过更好的硬件和芯片架构,在计算效率上进一步带来10倍的提升。

人工智能核心计算芯片发展趋势
目前,根据计算模式,人工智能核心计算芯片的发展分为两个方向:一个是利用人工神经网络从功能层面模仿大脑的能力,其主要产品就是通常的CPU、GPU、FPGA及专用定制芯片ASIC。另一个神经拟态计算则是从结构层面去逼近大脑,其结构还可进一步分为两个层次,一是神经网络层面,与之相应的是神经拟态架构和处理器,如IBM的TrueNorth芯片,这种芯片把数字处理器当作神经元,把内存作为突触。与传统冯诺依曼结构不同,它的内存、CPU和通信部件完全集成在一起,因此信息的处理完全在本地进行,克服了传统计算机内存与CPU之间的瓶颈。同时神经元之间可以方便快捷地相互沟通,只要接收到其他神经元发过来的脉冲(动作电位),这些神经元就会同时做动作。二是神经元层面,与之相应的是元器件层面的创新。如IBM苏黎世研究中心宣布制造出世界上首个人造纳米尺度随机相变神经元,可实现高速无监督学习。
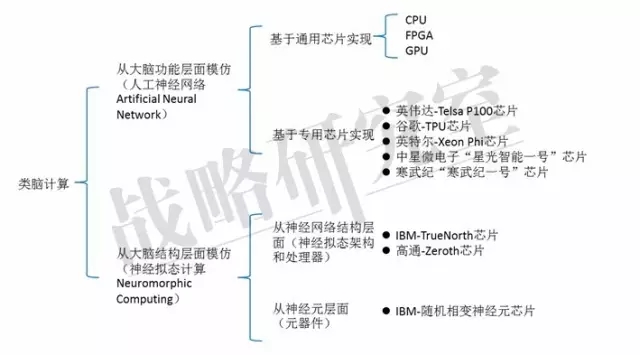
人工智能类脑芯片主要类型
从人工智能芯片所处的发展阶段来看,从结构层面去模仿大脑运算虽然是人工智能追求的终极目标,但距离现实应用仍然较为遥远,功能层面的模仿才是当前主流。因此CPU、GPU和FPGA等通用芯片是目前人工智能领域的主要芯片,而针对神经网络算法的专用芯片ASIC也正在被Intel、Google、英伟达和众多初创公司陆续推出,并有望将在今后数年内取代当前的通用芯片成为人工智能芯片的主力。
人工智能芯片(二):GPU
“人工智能算法的实现需要强大的计算能力支撑,特别是深度学习算法的大规模使用,对计算能力提出了更高的要求。”
传统的通用CPU之所以不适合人工智能算法的执行,主要原因在于其计算指令遵循串行执行的方式,没能发挥出芯片的全部潜力。与之不同的是,GPU具有高并行结构,在处理图形数据和复杂算法方面拥有比CPU更高的效率。对比GPU和CPU在结构上的差异,CPU大部分面积为控制器和寄存器,而GPU拥有更多的ALU(ARITHMETIC LOGIC UNIT,逻辑运算单元)用于数据处理,这样的结构适合对密集型数据进行并行处理。CPU执行计算任务时,一个时刻只处理一个数据,不存在真正意义上的并行,而GPU具有多个处理器核,在一个时刻可以并行处理多个数据。程序在GPU系统上的运行速度相较于单核CPU往往提升几十倍乃至上千倍。随着英伟达、AMD等公司不断推进其GPU的大规模并行架构支持,面向通用计算的GPU(即GPGPU,GENERAL PURPOSE GPU,通用计算图形处理器)已成为加速可并行应用程序的重要手段。
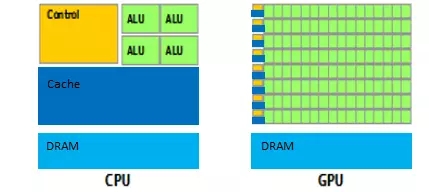
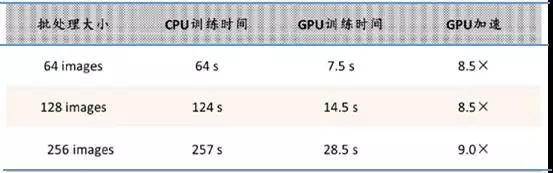
CPU及GPU结构及功能对比
GPU的发展经历了三个阶段:第一代GPU(1999年以前),部分功能从CPU分离,实现硬件加速,以GE(GEOMETRY ENGINE)为代表,只能起到3D 图像处理的加速作用,不具有软件编程特性。
第二代GPU(1999-2005年),实现进一步的硬件加速和有限的编程性。1999年英伟达GEFORCE 256将T&L(TRANSFORM AND LIGHTING)等功能从CPU分离出来,实现了快速变换,这成为GPU真正出现的标志;2001年英伟达和ATI分别推出的GEFORCE3和RADEON 8500,图形硬件的流水线被定义为流处理器,出现了顶点级可编程性,同时像素级也具有有限的编程性,但GPU 的编程性比较有限。
第三代GPU(2006年以后),GPU实现方便的编程环境可以直接编写程序;2006年英伟达与ATI分别推出了CUDA(COMPUTER UNIFIED DEVICE ARCHITECTURE,统一计算架构)编程环境和CTM(CLOSE TO THE METAL)编程环境;2008年,苹果公司提出一个通用的并行计算编程平台OPENCL(OPEN COMPUTING LANGUAGE,开放运算语言),与CUDA绑定在英伟达的显卡上不同,OPENCL和具体的计算设备没有关系。
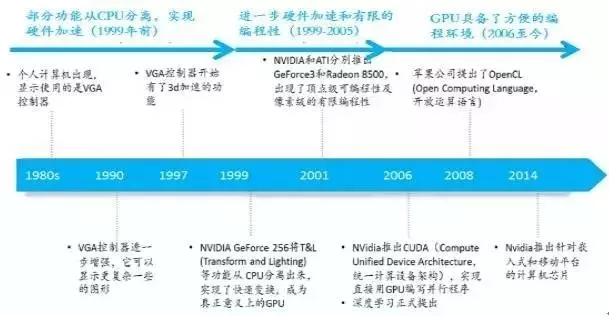
GPU芯片的发展阶段
目前,GPU已经发展到较为成熟的阶段。谷歌、FACEBOOK、微软、TWITTER和百度等公司都在使用GPU分析图片、视频和音频文件,以改进搜索和图像标签等应用功能。GPU也被应用于VR/AR 相关的产业。此外,很多汽车生产商也在使用GPU芯片发展无人驾驶。
根据研究公司TRACTICA LLC 预测,用于人工智能的GPU将从2016年的不到一亿美元增长到2025年的140亿美元,GPU将出现爆炸式增长。
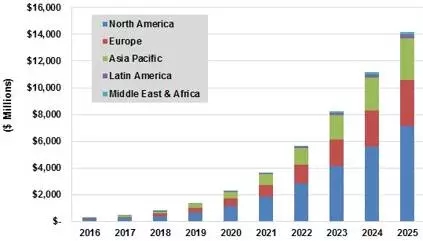
2016-2025年不同区域人工智能GPU收入预测(来源:TRACTICA)
近十年来,人工智能的通用计算GPU完全由英伟达引领。2010年英伟达就开始布局人工智能产品,2014年宣布了新一代PASCAL GPU芯片架构,这是英伟达的第五代GPU架构,也是首个为深度学习而设计的GPU,它支持所有主流的深度学习计算框架。2016年上半年,英伟达又针对神经网络训练过程推出了基于PASCAL架构的TESLA P100芯片以及相应的超级计算机DGX-1。对于TESLA P100,英伟达首席执行官黄仁勋称这款GPU的开发费用高达20亿美元,而英伟达全年的营收也不过才50亿美元。深度学习超级计算机DGX-1包含TESLA P100 GPU加速器,并采用英伟达NVLINK互联技术,软件堆栈包含主要深度学习框架、深度学习SDK、DIGITS GPU训练系统、驱动程序和CUDA,能够快速设计深度神经网络(DNN)。拥有高达170TFLOPS的半精度浮点运算能力,相当于250台传统服务器,可以将深度学习的训练速度加快75倍,将CPU性能提升56倍,报价12.9万美元。2016年9月北京GTC大会上,英伟达针对神经网络推理过程又推出了基于PASCAL的产品TESLA P4/P40。
AMD则在2016年底集中发布了一系列人工智能产品,包括3款图形加速卡(品牌名MI),4款OEM机箱和一系列开源软件,以及下一代VEGA架构的GPU芯片。未来,AMD希望MI系列硬件加速器、ROCM 软件平台和基于ZEN的32核以及64核服务器CPU三者合力,为超算客户提供一整套基于AMD产品线的解决方案。
除了英伟达和AMD之外,INTEL计划在2017年将深度学习推理加速器和72核至强XEON PHI芯片推向市场。除了传统的CPU、GPU大厂,移动领域的众巨头在GPU的布局也非常值得关注。据说苹果也在搜罗GPU开发人才以进军VR市场,目前苹果A9的GPU性能与骁龙820相当,A9 GPU采用
查看评论 回复