
Arm TechCon 2019大事件盘点-嵌入式-
一年一度的Arm TechCon在今年盛大召开,来自世界各大科技巨头的专家们集结一起,商讨未来科技的发展趋势和政策方向。在过去的几年里,Arm一直致力于“第五波计算”――人工智能、物联网和5G的融合,以及由此产生的新的数据消费模型。值得期待的是,每一届的TechCon都会有“大事件”发生,还记得在第一届Arm TechCon上,当时的谷歌正在关注一个名不见经传的初创公司Android,马克・扎克伯格刚刚推出了facebook,Apple CEO 史蒂夫乔布斯正在探讨手机还是否需要按键…而如今他们都已声名鹊起。
下面我们就一起回顾一下2019年的Arm TechCon都有什么“大事件”。
Arm瞄准加强低功耗芯片客制化
在移动互联网时代,Arm显然是绝对的主流;就在这次大会上,Arm CEO Simon Segars 表示,成立近 30 年来,在1000多个合作伙伴的推动下,Arm核心的出货量已经超过 1500 亿。但随着移动互联网时代的结束和 IoT 时代的到来,Arm已经感受到了来自 RISC-V的压力。
为应对这一冲击,Arm在这次大会上宣布了自定义指令集功能――Arm Custom instructions,该功能允许客户在特定的 CPU 内核中加入自定义指令功能,从而来加速特定的用例、嵌入式和物联网应用程序。

据了解,Arm Custom Instructions 功能适用于 Cortex-M33 内核及以后的 Cortex-M CPU 系列。从 2020 上半年起,所有使用上述 CPU 内核的 Arm 客户都可以免费使用自定义指令功能;也就是说,Arm 不会对新的或既有授权厂商收取额外费用,同时让系统单芯片(SoC)设计人员在没有软件碎裂风险下,得以针对特定嵌入式与物联网应用加入自己的指令。
Arm表示将在最新的Armv8-M架构中添加“Arm Custom Instructions”功能。此举是为了让客户可以将针对嵌入式和物联网应用的特定指令添加到CPU中。Armv8-M架构是Arm现有M33 Cortex-M低功耗处理器系列的基础架构,该系列处理器主要面向一系列物联网和移动设备。
目前Arm阵营的芯片设计厂商仅有少数芯片设计厂商有购买ARMv8指令集授权来自行设计CPU内核,比如苹果的A系列处理器的CPU、华为的鲲鹏系列处理器的CPU等。但是,绝大多数的芯片设计厂商都是采用的Arm已经设计完成的内核IP,即外界常说的公版内核,各项性能指标都是已经完全定型了的。以CPU和GPU为例,它们之间通过系统总线交换数据的步骤:
第一步:CPU从文件系统里读出原始数据,分离出图形数据,然后放在系统内存中,这个时候GPU在发呆。
第二步:CPU准备把图形数据交给GPU,这时系统总线上开始忙了,数据将从系统内存拷贝到GPU的显存里。
第三步:CPU要求GPU开始数据处理,现在换CPU发呆了,而GPU开始忙碌工作。当然CPU还是会定期询问一下GPU忙得怎么样了。
第四步:GPU开始用自己的工作间(GPU核心电路)处理数据,处理后的数据还是放在显存里面,CPU还在继续发呆。
第五步:图形数据处理完成后,GPU告诉CPU,我忙完了,准备输出或者已经输出。于是CPU开始接手,读出下一段数据,并告诉GPU可以歇会了,然后返回第一步。
其他内核通过内存映射与CPU进行数据交换,都会遇到一个问题,那就是处理器的加速始终是受到总线速度的影响,并且会出现一定的延迟。当然,芯片设计厂商也可以选择直接连接到CPU的协处理器的解决方案,但是毕竟是两个独立的模块,数据交换也存在着延迟。
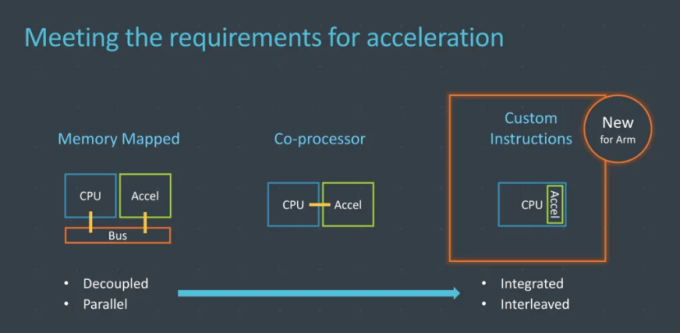
现在Arm在CPU内核当中引入自定义指令功能,则意味着,芯片设计厂商可以创建自己的加速算法,然后直接在CPU上运行,不需要像内存映射解决方案那样,需要通过总线来并行运行,所以可以在一定程度上进行加速,并进一步降低延迟。
Simon Segars介绍:“在芯片中增加灵活性是有空间的,例如增加了并非所有工作负载都需要的计算或安全功能。”而这一届发布的Arm Custom Instructions让芯片设计人员可以向其M33 Cortex-M CPU中添加“自定义数据路径扩展”。Arm表示,通过这种方式他们就可以打造各种加速器,从而在人工智能、机器学习和自动驾驶汽车等边缘计算用例实现更高的性能。
另外,ARM 方面表示,新增的 Arm Custom Instructions 功能,结合此前 Arm 推出的 Arm Flexible Access 计划,都是为了致力于增强芯片合作伙伴的灵活性和差异化,以支持机器学习、人工智能、自驾车、5G 与物联网等全新边缘运算的机会――为此,Arm Custom Instructions 在未来的 Arm Cortex-M CPU 上将变成标准功能,使这款CPU成为Arm历来最成功的CPU之一。
Arm希望将于明年上半年在其M33 CPU中实现自定义指令,而无需向被许可方支付任何额外费用。
Mbed引入全新模型
这次大会上Arm宣布了将为针对低功率物联网设备的Mbed操作系统引入一种新的治理模型。Mbed OS包含了开发人员基于Arm Cortex-M微控制器开发连接产品所需的所有功能,包括安全性、连接性、RTOS,以及用于传感器和I/O设备的驱动程序。
这对于Arm在IoT生态系统内推动持续创新与差异化是相当重要的一步。透过这个模型,Arm对半导体合作伙伴授权,让他们有能力帮助塑造与决定Mbed OS的未来方向,同时仍保有Arm多年来提供的强大商业领导地位与支持。
简单了解一下Mbed OS
Mbed OS一直是一套开放原始码的IoT操作系统,Arm正转移其管理权,让半导体伙伴拥有更大的自主权,能够直接影响这套系统未来的发展,并强化其打造新能力、新特色与新功能的能力,这对于未来万亿个联网设备的IoT发展来说极为关键。为实现这一目标,Arm推出新机制,其中包括每月召开一次产品工作群会议,会议中Arm与半导体伙伴们将投票决定那些新能力会优先加入至Mbed OS中,也欢迎所有Mbed半导体伙伴计划(Mbed Silicon Partner Program)成员免费加入。多家半导体合作伙伴,包括亚德诺半导体、赛普拉斯半导体、Maxim Integrated、新唐科技、恩智浦半导体、瑞萨电子、瑞昱半导体、三星、芯科科技与u-blox,都已积极参与这个工作群。
据了解,Mbed OS Partner Governance治理模型让用户在未来操作系统开发过程中拥有更多发言权,从而加强创新。伴随这个新模型的推出,Arm将成立一个新的产品工作组,该工作组每月开一次会,以应优先考虑哪些新Mbed OS功能进行投票,而且会议对Mbed Silicon合作伙伴计划的所有成员开放。
在共同架构下推动全面运算(Total Compute)
Arm推出了全新IP设计总体计算方法,Arm表示,该方法将更深入地关注性能、安全性和开发人员访问,以在人工智能、XR和物联网等领域推动更浸入式的数字体验。Arm表示,要达到数字沉浸所需要的性能,必须超越当前的水准,并朝Total Compute的世界迈进。这需要在设计IP时采用一种截然不同的方法,必须深度聚焦在性能、安全性与开发人员介入权的优化。Arm表示将依靠软件和工具,如Arm NN和Arm计算库以及开放标准和开源社区来实现这一目标。

自从推出Cortex-A73后,Arm便逐步且逐代地提升机器学习(ML)性能;今天,我们正在努力大幅拓宽针对ML的CPU覆盖。为了实现这个全新的数字世界,计算能力必须被推升至全新的水平,因此Arm将Matrix Multiple(MatMul)加入到新一代的Cortex CPU“Matterhorn”中,令其ML性能与前代CPU相比提升一倍。
ARM联手Unity,将AI学习性能提升到新水平
Arm宣布将与Unity Technologies合作,以确保3D应用程序(例如游戏和娱乐)在使用Arm架构的硬件上流畅运行。该公告是硬件和软件设计中更大的全面计算协作方法的一部分。

Arm Total Compute代表了一种IP设计的新方法,重点是用驱动的优化系统解决方案。在这种情况下,开发人员将为其软件编写软件开发套件,从而找出在中央处理器(CPU),图形处理单元(GPU)或机器学习(ML)硬件上处理该软件的最佳方法。 Arm的客户小组副总裁在接受采访时表示,这取决于在给定的功率范围内处理软件的最佳方法。作为Total Compute的一部分,Arm和Unity Technologies正在扩展战略合作伙伴关系,以进一步提高性能。

如今,Arm设备广泛被用于各种娱乐和游戏设备,从智能手机到虚拟现实和增强现实耳机。他说,通过这种方式,与Unity的合作才有意义。Arm和Unity正在扩展到各种3D内容,尤其是VR和AR,要使其在具有计算约束的所有平台上最佳工作,就需要进行大量工作.通过与Unity合作,我们可以做到这一点,以便他们和他们的工具了解如何优化以获得最佳渲染和性能。

Arm的Ian Smythe宣布全面计算工作
Arm现已开始作为Total Compute的一部分推出诸如存储标签扩展(MTE)之类的创新安全功能,以满足客户的各种需求。Google最近宣布了与我们合作设计用于Android设备的MTE的计划。这些功能与平台安全体系结构(PSA)相结合,将有助于对整个生态系统的安全性进行标准化和碎片整理。
瞄准自动驾驶,ARM宣布成立自动驾驶汽车计算联盟
ARM 宣布已携手多家合作伙伴,成立了自动驾驶汽车计算联盟,成为自驾汽车计算协会(AVCC)的创始会员。鉴于自动驾驶汽车的开发极其复杂,ARM 才决定成立该联盟,以协作的方式来解决各种安全和计算问题。AVCC会员包括通用汽车(General Motors)、丰田汽车(Toyota)、Denso、德国大陆(Continental)、博世(Bosch)、恩智浦半导体与NVIDIA。

加速大规模交付更安全、更负担得起的自驾汽车
如何才能让可部署的自驾汽车成为现实?这需要倾听、学习与采取行动。部署自驾汽车有许多重大的挑战,包括在车辆能耗、热能与尺寸的限制下,实现超高性能计算,从而运作大型且复杂的自驾软件堆栈。
AVCC部署自驾汽车必须克服的技术复杂性与障碍有着充分的了解,未来的目标是共同努力推出一个概念性计算平台,以应对这些挑战。这个组织集结了独特的专业专长与共同目标,而其第一个目标就是定义一个参考性架构与平台,以便在车辆部署实际性与经济性的限制下,达成自驾汽车的性能目标。这一计算平台的设计用意就是要让目前的原型机系统,想大规模部署演进,并针对自动驾驶系统中每一个基础组成组件制定相应的软件API的需求。
AVCC呼吁所有有兴趣的组织以及全球汽车生态系统的成员,共同接受打造产业未来的挑战,一步一脚印地寻求逐步突破,同时与科技界共享每一个重要进展。
Project Cassini 赋能AI边缘
利用AI边缘的应用程序的成功部署,关键在于提供能够覆盖各种功耗与性能需求的多元解决方案。单一厂商的解决方案,并无法满足所有需求。除了变成以AI为中心,AI边缘必须是云端原生的、虚拟化(VM或containers)的,同时支持多用户。最重要的是,它必须是安全无虞。
为了协助大家面对这一AI边缘的变革,Arm在此次大会上宣布推出Project Cassini:这是一个专注于在多元与安全的边缘生态系统内,确保云端原生体验的业界提案。
与Arm做生意将会越来越容易
在这个宏大的计划中,我认为Arm并没有从重要性和投资相称的知识产权许可中赚到多少钱。但有一些业内人士表示,Arm希望在授权和客户定制指令方面更加灵活,尤其是在低层控制器和物联网应用方面。
Arm允许开发人员在全面购买之前试用它的技术,这种“买之前先试一试”的服务方式似乎让Arm与客户变得更易于打交道了。根据Arm的说法,企业只会对在流片时使用的IP收取费用,这意味着如果项目暂停、更改或停止,将不收取任何许可费。这个决定是几个月前宣布的,现在只适用于物联网IP,智能手机、个人电脑、汽车或基础设施IP还未能包括,这些构成了75%的许可。
总结
回想2004年首届Arm开发者大会DevCon(开发者大会在2009年的时候从DevCon更名为TechCon)上,Arm主席Robin Saxby发表了“数字世界的演变”的主题演讲。他预测,二十年后,我们将能够以最基本简单的方式改善生活的技术:比如健康监测,更好的患者护理和药物输送,以及可以在我们体内使用的纳米技术。
现在来看,我们已经成功实现了Saxby的二十年愿景:Arm正在改善生活,提供健康监控,并在更多以人为本的功能中改善患者护理。如今的Arm TechCon已不仅仅是单纯的主题演讲,而是Arm生态系统布局的一部分,通过与会者的探讨交流,共同探索如何使用Arm技术来构建未来。
查看评论 回复








