
详细解读人工智能语音芯片 -嵌入式-
行业简介
人工智能芯片(简称AI芯片)是指含有专门处理人工智能应用中大量计算任务模块的芯片,属于集成电路和人工智能的交叉领域。自2016年以来,谷歌、百度、阿里、腾讯等互联网巨头以及多家知名的风险投资基金疯狂涌入人工智能行业,大力推动各初创算法(方案)公司在多个应用领域商业化落地。随着人工智能在视觉识别、语音识别等领域明确的商业化应用不断涌现,人工智能算法及方案芯片化、硬件化的趋势日益明显,具有深度学习算法加速功能的芯片需求快速提升。
人工智能领域的高速发展,取决于对前沿算法的研究、落地应用场景的积极探索及通过先进的芯片设计、制造技术来满足日益明确的商业需求三个关键因素。商汤科技、旷视科技、科大讯飞、思必驰、华为、寒武纪等多家中国公司对于前沿算法的研究已经走在全球前列,与美国齐头并进。中国对于落地应用的探索更是全球领先,已经出现包括人脸识别、智能安防、智能音箱、智能家居等多个落地的商业场景。新一代的AI芯片创业公司结合应用特点,采用了合理的先进芯片设计、制造技术,与美国同类公司相比位于同一起跑线上。业界普遍认为,AI芯片之争是中美两国公司间的竞争,中国目前暂时落后。但由于在应用探索上更加积极,未来中国AI芯片有可能超越竞争对手,成为全球领军力量。
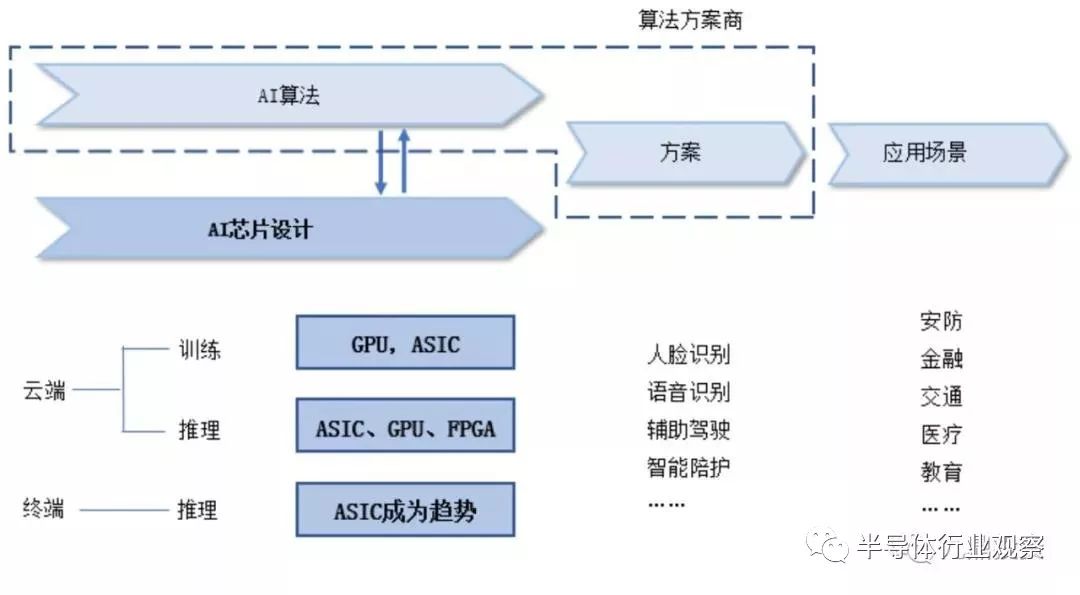
AI芯片按照应用场景可以分为云端芯片和终端芯片,按照功能可以分为训练芯片和推理芯片。云端指服务器端,终端指包括手机、电脑、监控摄像头、家电、消费电子等在内的电子终端产品。训练指通过大量的数据输入,运用增强学习等非监督学习方法,训练出一个复杂深度神经网络模型的过程,其对芯片运算和存储的综合性能要求很高。推理指利用训练好的模型,使用新的数据去得出各种结论、完成各种任务的过程,其对芯片的速度、能耗、安全和硬件成本要求较高。
按照以上两个维度,可以将AI芯片划分至四个象限。其中,终端/嵌入式设备以推断应用为主,训练的需求尚不是很明确,但是,未来的终端设备将逐步具备训练和学习的能力。
图1:AI芯片按照两个维度分类

资料来源:清华大学、北京未来芯片技术高精尖创新中心
发展历程
自芯片诞生以来,人类对芯片设计、高纯度硅工艺、超高精密设备、物理化学工艺的不断探索,促进了芯片技术的快速发展,芯片的计算能力呈指数形式增长,推动了个人计算机和互联网时代的诞生和发展。2006年,以深度学习算法为标志的新一代人工智能诞生,2016和2017年,基于深度学习技术、运行于TPU(ASIC)上的Google人工智能AlphaGo相继战胜人类围棋世界冠军李世石、柯洁,引发新一轮人工智能发展热潮,计算能力再次成为人工智能时代的核心驱动力。AI芯片则是计算能力提升的集中体现,成为人工智能“大脑”的基础。
2010年至今,不同功能和定位的芯片均开始被研发用于深度学习算法,初步形成了GPU、FPGA、ASIC等繁荣共生的AI芯片行业。
产业链及核心环节
AI芯片的设计、制造流程与其他芯片类似,由设计、制造、封装测试等环节组成。AI芯片设计公司下游为应用方案公司,方案公司将其整体解决方案(包括运行于云端和终端的各类软硬件)最终用于具体应用场景。目前处于AI领域发展初期,中国的算法公司投入大量资金及精力探索落地应用,算法公司与应用方案公司实际上已经合为一体。具体来看:
在下游应用环节,算法及方案公司根据不同的应用场景,制定云端和终端的芯片布局方案。其中,云端为应用场景训练可靠的人工智能算法,并承担大部分复杂的推理任务,终端直接为应用场景输出结果。目前,人工智能在安防、金融、医疗和教育等领域均获得了快速落地并形成了可推广的案例。
在上游环节,不同的人工智能算法对AI芯片的加速功能提出了不同要求,需要AI芯片设计公司根据算法特点,设计具有特定加速功能的芯片。按照推理和训练划分来看,训练环节所需的运算包括前向计算和后向更新,推断环节则主要是前向计算。前向计算包括矩阵相乘、卷积和循环层运算等,后向更新主要是梯度运算。所以,两个环节运算特点不尽相同。云端侧重训练,算法更加复杂和广泛,对芯片的通用性和综合性能要求更高;终端侧重推理,算法更加高效可靠,对芯片的专用性和效率要求更高。同时,由于芯片具有一旦设计完成基本不可更改的硬件属性,算法公司需要结合算法的发展现状在现有AI芯片技术条件下选择合适的芯片架构及软硬件功能划分。
综合来看,算法与AI芯片设计互相影响。作为AI芯片公司,需要充分了解和掌握算法规律,设计出符合发展需求的AI芯片;作为算法公司,需要在各类AI芯片,尤其是专用芯片的基础上,实现算法的演进。
图2:AI芯片产业链示意
资料来源:九鼎投资整理
行业壁垒
AI芯片行业属于人工智能和集成电路的交叉产业,具有双重属性,行业壁垒较高。
首先,人工智能行业存在两道壁垒。第一道壁垒是算法,只有掌握深度学习算法并具备持续更新算法的能力,才算真正进入人工智能的大门。第二道壁垒是对应用场景的理解,只有将算法在具体应用场景中落地,形成数据加算法的闭环,才能通过数据反哺算法,形成超越竞争对手的优势。
其次,芯片设计行业存在技术、人才、经验和资金的综合壁垒。芯片设计产业链环节多,需要多方面、多层次、多梯度的人才及丰富的量产工程化经验。需要采用先进制程的AI芯片,流片费用高达几千万,产品研发周期长达1-2年,新公司的进入门槛很高。
AI芯片格局和主要公司
目前,在训练环节,由于需要更高效地进行大规模并行计算,英伟达GPU占据垄断性地位,因特尔CPU+FPGA、谷歌TPU和寒武纪MLU等ASIC方案也在加速追赶。在推理环节,不同的异构芯片或专用芯片算力表现处在发展变化的过程中。云端推理方面,Intel的CPU+FPGA架构具有强大能力,英伟达也通过Volta架构大大提升了其GPU的推理性能;终端推理方面,由于更接近最终应用,不同的细分市场算法差别较大,ASIC由于专用性强、效率高、功耗低,成为主流选择,FPGA则适合用于算法方案快速变化的终端领域。
综合来看,未来可能呈现如下产业格局:GPU应用于高端复杂算法、高性能计算和数据中心;ASIC在云端训练、推理及智能终端广泛应用;FPGA 应用于变化较快的行业应用和虚拟化云平台。
表1:四类人工智能芯片对比

资料来源:九鼎投资整理
GPU和FPGA
1.GPU
GPU(Graphics Processing Unit)是一种进行图形运算工作的微处理器。随着通用计算技术发展,GPU的功能已经不再局限于图形处理,在浮点运算、并行计算等高性能计算方面开始有广泛的应用。目前支持金融工程学、气象及海洋建模、数据科学及分析、国防与情报、制造业(CAD制图及CED)、成像与计算机视觉、医学影像、电子设计自动化、计算化学等多个领域共150多种应用程序的加速。但由于其功耗较高,主要用于云端计算。
GPU是目前深度学习算法训练的首选芯片,在该领域拥有最高的市占率。其拥有完备的人工智能计算软件生态,越来越多的深度学习标准库支持基于GPU的深度学习加速。与CPU相比,GPU适用于密集型程序以及并行计算,而CPU擅长于逻辑运算和串行计算。
(1)英伟达(NVIDIA)
英伟达的GPU产品主要包括PC端处理器GeForce、移动处理器Tegra和深度学习芯片Tesla。其中Tesla的核心产品包括基于PASCAL架构和Volta架构的系列芯片。
目前英伟达的GPU产品主要应用于各类计算平台、数据中心加速和深度学习训练,应用领域包括医疗、汽车、智能家电、金融服务等。基于Tegra系列处理器,英伟达发布了DRIVE PX开放式人工智能车辆计算平台,可实现包括高速公路自动驾驶与高清制图在内的自动巡航功能,应用的特斯拉ModelS已经开始量产,百度、沃尔沃也跟英伟达达成了合作,他们都将生产搭载DRIVE PX的智能驾驶汽车。
英伟达2018年5月推出的Telsa V100浮点运算速度提高了1.5倍,深度学习训练速度提高了12倍,推理速度提高了6倍。
(2)ATI(被AMD收购)
ATI是与英伟达齐名的显卡制造商,2006年被AMD以54亿美元收购。2017年8月,AMD搭载深度学习功能的新一代GPU正式发布,在各项测试和应用中性能超过英伟达Pascal系列。2018年,AMD 公开展示了全球首款7纳米制程的GPU芯片原型。总体而言,AMD在产品生态和市场份额方面不如英伟达,但仍是全球仅次于英伟达的GPU厂商。
(3)景嘉微
景嘉微是国内唯一拥有自主知识产权和成熟产品的图形处理芯片公司。公司创建于2006年4月,2016年3月在深圳证券交易所挂牌上市,现有员工400多人。公司创新的MPPA架构提供单芯片超算解决方案,具有高性能、低功耗、实时性等特点,可以为视频、网络、电信、大数据等领域的云计算应用实现实时加速,还可以为航空航天、国防、汽车等领域的嵌入式应用提供嵌入式高性能运算能力。但是,景嘉微与国外GPU巨头技术差距较大,短期内尚无可能影响人工智能GPU芯片的产业格局。
2.FPGA
FPGA为现场可编程门阵列。高密度计算、大吞吐量和低功耗的特点使其在各个行业领域有较大的发展空间。在通信领域,FPGA主要用在通信和无线设备系统,为数据中心提供更高的能源效率、更低的成本和更高的扩展性,还可以用于 5G 的可编程解决方案;在工业领域,FPGA可实现自动化、机器视觉和运动控制;在汽车领域,FPGA成为 ADAS 的主要处理平台,提供实时图像分析与智能传输。由于 FPGA 可编程,其在提供差异化产品和快速响应上有着极大的优势。此外,CPU+FPGA 的混合结构也可用于云服务计算。
FPGA的市场发展迅速,但技术门槛比较高,目前市场上主要由Xilinx(赛灵思)与 Altera(阿尔特拉)两家公司主导,两家市场份额合计达80%以上。
(1)赛灵思(Xilinx)
Xilinx是全球排名第一的可编程逻辑完整解决方案的供应商。公司成立于1984年,Xilinx首创了现场可编程逻辑阵列(FPGA)这一技术,并于1985年首次推出商业化产品。Xilinx研发、制造并销售多种类型的集成电路、软件设计工具以及作为预定义系统级功能的IP(Intellectual Property)核。Xilinx产品已经被广泛应用于从移动通信基站到DVD播放机的数字电子应用技术中。作为FPGA技术的发明者和产业龙头型公司,Xilinx约占全球FPGA市场出货量的50%,在高端FPGA市场(16nm、20nm、28nm)占有较大优势。公司在全世界拥有7500多家客户,包括IBM、NEC、Samsung,Siemens、Sony等知名公司。
(2)阿尔特拉(Altera)
Altera在FPGA领域长期占据领先地位,是Xilinx之外另一家FPGA寡头级企业。Altera公司的FPGA分为两大类,一种侧重低成本应用,容量中等,性能可以满足一般的逻辑设计要求,如Cyclone,CycloneII;还有一种侧重于高性能应用,容量大,能满足各类高端应用,如Stratix,StratixII等。Altera的FPGA产品被广泛应用于汽车、消费电子、军事航空、医疗、无线通信等多个领域。
2015年末Intel斥资167亿美元收购了Altera公司。Intel计划将Altera的可定制芯片和自有的标准化半导体相整合,以针对网络搜索、机器学习等特定任务打造更加高效的产品解决方案。
(3)深鉴科技(被Xilinx收购)
深鉴科技提供基于FPGA平台的人工智能加速解决方案,2018年8月被赛灵思收购。深鉴科技在深度神经网络压缩、指令集与计算架构等领域具有技术领先优势,其关于深度压缩的论文与谷歌DeepMind的论文并列ICLR2016最佳论文。2016年Open Power峰会上全球最大FPGA厂商介绍深度学习处理器新方法中的技术部分大多来自深鉴科技。深鉴科技基于FPGA的DPU产品可为多行业提供深度学习加速解决方案。相对于CPU、GPU等通用化产品具有更高的能效,目前已经应用于安防、大数据等行业。
中国其他的FPGA芯片公司,包括京微齐力、高云、安路、智多晶等,普遍还未能量产高性能FPGA,短期内尚无可能影响人工智能FPGA的产业格局。
ASIC
ASIC(Application Specific Integrated Circuits)指针对特定需求而设计、制造的集成电路。神经网络处理器是ASIC专用电路在人工智能领域的应用形态。目前,国际龙头芯片厂商在GPU和FPGA领域对AI芯片应用竞争呈现白热化,而随着未来终端人工智能应用的兴起,为深度学习算法定制的ASIC芯片在计算速度和功耗上大大优于GPU和FPGA,伴随人工智能加速对行业渗透,未来在安防、智能终端、金融、车联网等领域,ASIC将得到广泛应用,广阔的市场空间使ASIC大规模应用成为可能。可以预见,专用AI芯片(ASIC)将成为新晋AI芯片领域厂商与传统巨头竞争的主战场。同时,我国专用AI芯片公司与世界领先水平差距不大,某些领域位于世界前沿,ASIC将成为我国芯片行业弯道超车的关键。
当前,国内已经出现了一些面向终端人工智能的ASIC芯片企业,大致可以划分为四类:一是互联网、通信类巨头的芯片设计团队;二是存在多年的成熟的芯片设计公司;三是新创立的AI芯片创业团队/公司;四是延伸做AI芯片的算法公司,
1.互联网、通信类巨头
以华为、百度等为代表的巨头公司,在算法、数据方面具有明显优势,为了延伸实现AI应用的落地,加快了芯片端的布局,但主要集中在云端芯片上。
(1)谷歌
谷歌的TPU(Tensor Processing Unit)是一种专用的加速器芯片,跟其深度学习软件Tensor Flow 匹配。TPU 专门针对机器学习进行裁减,运行单个操作时需要的晶体管更少,其研发目的是为了替代GPU,实现更高效率的深度学习。
TPU的设计不仅仅是针对某种神经网络模型,而是能够在多种神经网络(CNN、LSTM,以及大型全连接网络模型等)中执行CISC(复杂指令计算机)的指令。在TOPS / Watt(每瓦特性能)功耗效率测试中,TPU的性能要优于常规的处理器30到80倍;而同传统的GPU/CPU的计算组合相比,TPU的处理速度快15到30倍;更为关键的是,由于TPU的运用,深度神经网络所需要的代码数量也大幅的减少。在深度学习技术迅速发展,数据和算力要求快速提高的人工智能时代,谷歌的这一替代方案将为硬件大规模减负,进一步降低人工智能的硬件成本。
(2)华为海思
华为海思作为我国芯片领域的领军企业之一,2017年发布了全球首款AI移动端芯片麒麟970,抢先一步占领AI芯片制高点,引起业界广泛关注。麒麟970采用了行业高标准的TSMC 10nm工艺,集成了55亿个晶体管,实现了1.2Gbps的峰值下载速率,创新性地集成了NPU专用硬件处理单元,并设计了HiAI移动计算架构。
2018年9月,华为海思再次发布了新一代产品麒麟980。该产品基于CPU、GPU、NPU、ISP和DDR,实现了全系统融合优化的异构架构,并创下了六项世界第一:首次使用领先的TSMC 7nm制造工艺,首次在移动端芯片搭载双NPU,首先实现基于ARM Cortex-A76 CPU架构进行商业开发等。其中,搭载的寒武纪NPU采用双核结构,其图像识别速度比麒麟970提升120%。
此外,华为海思在监控SOC芯片领域市占率全球第一,其集成AI本地推断功能的监控SOC必将在市场中占据重要位置。
(3)百度
百度联合硬件厂商推出DuerOS智慧芯片,是百度在人工智能与硬件设备一体化方面的新探索。DuerOS智慧芯片拥有低成本芯片和模组,可以以芯片嵌入的形式放到任何硬件中,能够更加快速而广泛地应用到更多场景。可以看出,百度在利用“算法+芯片”的组合实现人工智能产业化落地。
2018年7月,百度发布首款云端AI芯片“昆仑”,这是百度基于八年的CPU、GPU和FPGA的AI加速器研发经验,在中国大规模AI运算实践中,经过20多次迭代产生的芯片。相对于谷歌TPU擅长浮点计算,百度AI芯片更擅长混合精度计算,一些场景下计算性能强2-3倍,同时功耗更低,将应用于未来的自动驾驶、图像识别等领域。
查看评论 回复








