¡°Î̉ĂǷdz£Ï£Íû ARM ºÍöïÅôµÄÉú̀¬ÄܳÉΪÏẨ»¸ö¼ÆËă²ú̉µµü´úµÄ·½Ị̈¡£¡±ÔÚ 6 Ô 8 ÈƠÓڳɶ¼¾Ù°́µÄ»ªÎª DevRun ¿ª·¢ƠßɳÁú¡ª¡ªËÄ´¨öïÅô¿ª·¢Ơß¼ÎÄ껪ÉÏ£¬»ªÎªöïÅô¼ÆËă²ú̉µ¿ªÔ´ÓëÉú̀¬ÓªÏú×ܼàÁº±ù¶Ô¼ÆËă²ú̉µÎ´À´Ơ¹ÍûµÀ¡£
Đ»ù½¨·ç¿ÚÏ£¬ËăÁ¦̉»Ô¾³ÉΪÁËеÄÉú²úÁ¦£¬ÔÆ¡¢AI Óë 5G ỘÊÇеÄÉú²ú¹¤¾ß£¬¼¼Êơ¾Û±ä½«̉ư·¢É̀̉µÁѱ䣬´ø¶¯¸÷Đи÷̉µµÄÊư×Ö»¯¿́ËÙ·¢Ơ¹¡£»ùÓÚ 5G µÈĐÂĐ˼¼ÊơµÄ´´ĐÂÓ¦ÓĂ´ßÉú¶àÑù»¯ËăÁ¦µÄĐèÇó£¬ÊĐ³¡¼ÈĐè̉ªÍ¨ÓĂ¼ÆËăËăÁ¦̉²Đè̉ª̉́¹¹¼ÆËăËăÁ¦¡£´ËÍ⣬Ħ¶û¶¨ÂɵÄÖđ½¥·Å»º£¬ÈĂËăÁ¦ºÍĐÔÄÜÏƯÈë̉»ÏµÁĐ·¢Ơ¹Æ¿¾±£¬ÊĐ³¡¶Ô´´Đ¼ܹ¹µÄĐèÇóÈỞæ¼ÓÉ¼ÆËăƽ̀¨µÄ´´ĐÂÖ®Ơ½̉»´¥¼´·¢¡£
Ôڴ˱³¾°Ï£¬x86 ¼Ü¹¹µÄ²»×ăÔ½·¢Ă÷ÏÔ£¬¹¦ºÄ´ó¡¢Í¨ÓĂ¼Ä´æÆ÷ÊưÁ¿ÉÙ¡¢¼ÆËă»úÓ²¼₫ÀûÓĂÂʵ͡¢Ñ°Ö··¶Î§Đ¡µÈÎỀâ͹ÏÔ£¬ÄÑ̉Ô¸úÉÏËăÁ¦·¢Ơ¹µÄËٶȡ£Óë´Ëͬʱ£¬ARM ¼Ü¹¹ÔÚ̉ƶ¯»¥ÁªÍøÊ¢Đеĵ±ÏÂÈ´¿ªÊ¼»À·¢³ö±đÑùµÄÉúĂüÁ¦¡£
¡°»ùÓÚ ARM ¼Ü¹¹À´Éè¼ÆµÄöïÅô£¬Æä³É¹¦µÄÇ°̀áÊÇÔçÔçµØ±ă¿´µ½ÁËδÀ´¼ÆËă»úËăÁ¦¼Ü¹¹µÄµü´ú֮·¡£¶Ô»ªÎªÀ´Ëµ£¬²»¹ẩªÔÚÖĐ¹úĐ¯ÊÖºÏ×÷»ï°é¹²½¨öïÅôÉú̀¬£¬Îª¸ü¶àÆó̉µ´øÀ´¼ÛÖµ£¬¸üΪÖØ̉ªµÄÊÇ̉ªÈÚÈëÈ«Ç̣ ARM µÄÉú̀¬£¬¹²Í¬Íƽø ARM ½ø½×ΪÏẨ»´ú¼ÆËă»úƽ̀¨µÄÊÂʵ±ê×¼¡£¡±Áº±ù¶ÔöïÅôÉú̀¬µÄ̉ẩå²ûÊöµÀ¡£
´Ó x86 Ǩ̉Ƶ½ ARM ¼Ü¹¹µÄ¹ư³̀²¢²»¼̣µ¥£¬±¾´Î»î¶¯ÖĐ£¬»ªÎªöïÅô¼ÆËăר¼̉¶ÔÓÚöïÅôÈí¼₫Ǩ̉Æ·¾¶̉²½øĐĐÁ˷dz£È«ĂæϸÖµĽ²½â£¬Í¬Ê±Ơë¶ÔÈí¼₫Ǩ̉ƹư³̀ÖĐ¿ÉÄÜÓöµ½µÄÎỀâ¼°½â¾ö·½°¸̉²½øĐĐÁËÏà¹Ø½²½â£¬»¹ÎªÏÖ³¡¿ª·¢ƠßÉèÖĂÁËʵ²ÙÑƯÁ·»·½Ú£¬̉»¶Ổ»Ö¸µ¼Ï½øĐĐöïÅôÈí¼₫Ǩ̉ÆÏßÉÏʵÑé¡£
´Ó x86 Ị̈öïÅôǨ̉ƵıØ̉ªĐÔÖÚËùÖÜÖª£¬¼ÆËă»úÊÇÓÉÈí¼₫ºÍÓ²¼₫×é³ÉµÄ£¬ÉϲăµÄÈí¼₫ÊÇͨ¹ưÖ¸ÁÇư¶¯Ï²ăµÄÓ²¼₫£¬Èí¼₫Ïë̉ªÅÜÔÚ CPU ÉϵĻ°£¬ÄÇËü±ØĐë̉ªÓжÔÓ¦µÄÖ¸Á¡£
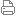
ÈçÉÏͼËùʾ£¬Ơû¸ö¼ÆËă»úµÄ¼ÆËă»ù´¡¼Ü¹¹£¬´Óµ×²ăµÄ¾§̀å¹Ü¡¢ÎïÀíÔ²ÄÁÏ£¬¶₫¼«¹Ü̉²¾ÍÊÇÂß¼Ăŵç·£¬µ½ÍùÉÏ×ßµÄ΢¼Ü¹¹¡¢×ÔÆÀ¼¶¼Ü¹¹£¬ÔÙÍùÉÏĂæ×߾͵½Á˲Ù×÷ϵͳËùÍê³ÉµÄ¶₫½øÖÆ»úÆ÷̉ëÂë»ă±à¸ß¼¶ÓïÑÔ¡¢JavaC µÈµÈ£¬Ơû¸ö¼¼ÊơƠ¾´Ó¸´ÔÓµ½³éÏ󣬼¼ÊơÓïÑỔ²´Ó¾Àú̉»¸ö¼̣µ¥µÄ½»»»Ö¸Áî·¢Ơ¹Îª»ă±à½øĐĐ·Ă´æºÍËø´æ£¬ÔÙµ½ĐγɻúÆ÷Â룬Ơâ¸ö¹ư³̀ÖĐ×îºËĐĵı仯ÔÚÖ¸ÁÉÏ¡£
Ïë̉ª³É¹¦ÔËĐĐ£¬µ×²ă¼ÆËăƽ̀¨¾Í±ØĐëÄܹ»Ö§³Ö¸Ă CPU µÄÖ¸Áî²Å¿É̉Ô£¬Ơẩ²ÊÇÔÚ x86 ºÍöïÅô±à̉ëµÄ²»Í¬Ö®´¦¡£
ÈçÉÏͼËùʾ£¬x86 ºÍöïÅôʹÓõÄÖ¸ÁîÊDz»̉»ÑùµÄ£¬¼̣µ¥À´½²£¬ÔÚöïÅôÉÏʹÓõÄÊǾ«¼̣Ö¸Á£¬¶øÔÚ x86 ÉÏʹÓõÄÊÇ̉»¸ö¸´ÔÓµÄÖ¸Á¡£×ÛºÏÀ´½²£¬ËüÓĐÈưµăÖ÷̉ªµÄ²î̉́£º






 ·¢±íÓÚ 2020-6-13 13:38:49
·¢±íÓÚ 2020-6-13 13:38:49
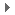
 ÊƠ²Ø
ÊƠ²Ø