
如何用Python写一个抓取新浪财经网指定企业年报的脚本?
来源:网络整理 网络用户发布,如有版权联系网管删除 2018-08-13
问题描述如下:
题主会计学二专毕业设计论文DDL在即,做的是分析食品企业会计信息与股价的实证课题,目前需要从新浪财经上收集100家食品企业近五年的财报,如果手动收集的话是根据证监会2014年4季度上市公司行业分类结果上的上市公司股票代码输到股票首页_新浪财经 的搜索框,然后再从所选公司的网页(如康达尔(000048)股票股价,行情,新闻,财报数据)上点选“公司年报”,下载近五年的年报数据。
所选企业是2014年4季度上市公司行业分类结果上所有13、14、15大类,有100多家,全部手动收集的话工作量略大,想问下有没有办法用Python写一个脚本完成以上工作?(大学修过一门用python讲的计算思维,算是有一点点python基础吧)
感激不尽~
参考答案如下:
嗨~我来答题了~
虽然题主已经搞定了问题……
提问后一周已经搞定了,用了excel power query+yahoo finance api 等这周忙完毕业设计回来更新问题…还是非常感谢~!就当练手了~问题的解决办法有很多。利用现有的api挺方便。不过我还是按照题主原来的思路笨办法写写试试。
老规矩边做边调边写~
#新手 很笨 大神求不喷 新手多交流
#start coding
第一步自然是搜集股票代码…用在线的PDF2DOC网站,然后把13、14、15三类的股票代码复制粘贴到一个文本文档里。像这样…
 然后我们需要让Python按行读入文本文档里的内容并存入一个列表。很简单。
然后我们需要让Python按行读入文本文档里的内容并存入一个列表。很简单。f=open('stock_num.txt')stock = []for line in f.readlines(): #print(line,end = '') line = line.replace('n','') stock.append(line)f.close()print(stock)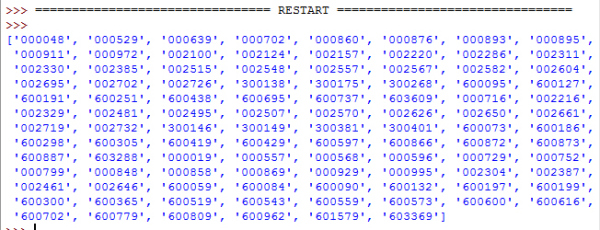 然后我们看怎么到网页里找到下载文件的链接。
然后我们看怎么到网页里找到下载文件的链接。题主想的步骤还是复杂了,分析一下新浪财经的网址构成就好。
例如康达尔(000048)年度报告
#http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/000048/page_type/ndbg.phtml#网址构成中只要更改stockid/六位数字 就可以进入任一股票的年报页面for each in stock: url='http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/'+each+'/page_type/ndbg.phtml'Firefox F12。
 很显然~地址有了~
很显然~地址有了~我们只要在年报列表的页面里匹配所有符合条件的页面就好。
但是进入了这个页面并不是最终的PDF下载页面。
想要最终获取下载页面还得多走一步。


好,到此为止,我们就一步一步地找到了一个年报的下载地址……那我们需要下载所有股票的所有年报(没有区分近五年)怎么做?两步循环就好。
循环股票代码,得到他们的年报列表,再循环年报列表,下载所有年报~
我们先来试试下载一支股票的所有年报。
还是以康达尔(000048)年度报告为例吧。
import urllib.requestimport reimport os#http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid=000048&id=1422814#http://file.finance.sina.com.cn/211.154.219.97:9494/MRGG/CNSESH_STOCK/2009/2009-3/2009-03-10/398698.PDF url='http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/'+'000048'+'/page_type/ndbg.phtml'req = urllib.request.Request(url)req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0')page = urllib.request.urlopen(req)html = page.read().decode('utf-8')target = r'&id=[_0-9_]{6,7}'target_list = re.findall(target,html)print(target_list) 报错也不要害怕~解决就是了。编码错误…去查看网页的编码
报错也不要害怕~解决就是了。编码错误…去查看网页的编码 把代码里的utf-8改成gb2312 不重复贴了,重新运行。
把代码里的utf-8改成gb2312 不重复贴了,重新运行。#后面我改成gbk了……编码什么的经常出错,不赘述。自己遇到坑就懂了。
 得到了所有年报的地址页面。
得到了所有年报的地址页面。然后我们尝试下载其中一个年报。
以康达尔(000048)_公司公告为例。
我们新建一个以股票代码命名的文件夹保存PDF。
import urllib.requestimport reimport osos.mkdir('./000048')target_url='http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid=000048'+'&id=712408'treq = urllib.request.Request(target_url)treq.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0')tpage = urllib.request.urlopen(treq)thtml = tpage.read().decode('gbk')#print(thtml)file_url = re.search('http://file.finance.sina.com.cn/211.154.219.97:9494/.*?PDF',thtml)print(file_url.group(0))local = './'+'000048'+'/'+file_url.group(0).split("/")[-1]+'.pdf'urllib.request.urlretrieve(file_url.group(0),local,None)

至此我们可以确定能下载成功
开始完善循环。
下载某一股票所有年报。
import urllib.requestimport reimport osurl='http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/'+'000048'+'/page_type/ndbg.phtml'req = urllib.request.Request(url)req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0')page = urllib.request.urlopen(req)html = page.read().decode('gbk')target = r'&id=[_0-9_]{6}'target_list = re.findall(target,html)os.mkdir('./000048')for each in target_list: print(each) target_url='http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid=600616'+each treq = urllib.request.Request(target_url) treq.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0') tpage = urllib.request.urlopen(treq) thtml = tpage.read().decode('gbk') #print(thtml) file_url = re.search('http://file.finance.sina.com.cn/211.154.219.97:9494/.*?PDF',thtml) print(file_url.group(0)) local = './000048/'+file_url.group(0).split("/")[-1]+'.pdf' #写入一个空文件站位,实际使用时使用urlretrieve可以下载文件 open(local, 'wb').write(b'success') #urllib.request.urlretrieve(file_url.group(0),local,None) 果然没有一帆风顺的事情。不过不要怕,我们看一下是哪里出错了。
果然没有一帆风顺的事情。不过不要怕,我们看一下是哪里出错了。打开&id=1394915这个页面。康达尔(000048)_公司公告
 诶,这个页面里根本没有下载链接。也就是说我们在匹配下载地址的时候返回了None。
诶,这个页面里根本没有下载链接。也就是说我们在匹配下载地址的时候返回了None。我们使用try语句处理异常,遇到没有下载链接的页面输出“失效”。
修改代码如下:
import urllib.requestimport reimport osurl='http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/'+'000048'+'/page_type/ndbg.phtml'req = urllib.request.Request(url)req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0')page = urllib.request.urlopen(req)html = page.read().decode('gbk')target = r'&id=[_0-9_]{6,7}'target_list = re.findall(target,html)os.mkdir('./000048')for each in target_list: print(each) target_url='http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid=600616'+each treq = urllib.request.Request(target_url) treq.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0') tpage = urllib.request.urlopen(treq) thtml = tpage.read().decode('gbk') #print(thtml) try: file_url = re.search('http://file.finance.sina.com.cn/211.154.219.97:9494/.*?PDF',thtml) print(file_url.group(0)) local = './000048/'+file_url.group(0).split("/")[-1]+'.pdf' #写入一个空文件站位,实际使用时使用urlretrieve可以下载文件 open(local, 'wb').write(b'success') #urllib.request.urlretrieve(file_url.group(0),local,None) except: print('失效')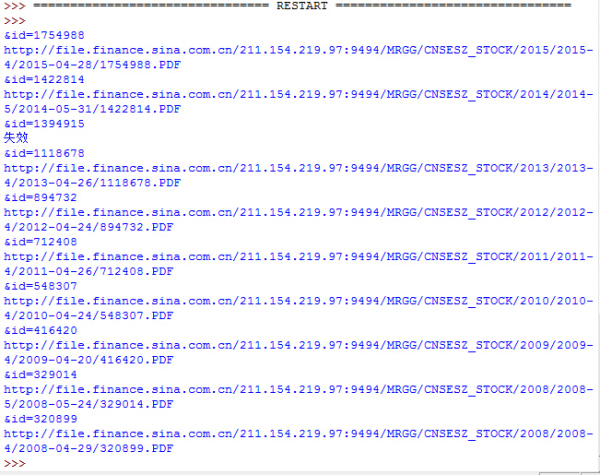
 看上去很完美……加上外层stockid再循环试试…
看上去很完美……加上外层stockid再循环试试…import urllib.requestimport reimport osf=open('stock_num.txt')stock = []for line in f.readlines(): #print(line,end = '') line = line.replace('n','') stock.append(line)f.close()#print(stock)for each in stock: url='http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/'+each+'/page_type/ndbg.phtml' req = urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0') page = urllib.request.urlopen(req) html = page.read().decode('gbk') target = r'&id=[_0-9_]{6}' target_list = re.findall(target,html) os.mkdir('./'+each) sid = each #print(target_list) for each in target_list: #print(a) #print(each) target_url='http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid='+sid+each #print(target_url) treq = urllib.request.Request(target_url) treq.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0') tpage = urllib.request.urlopen(treq) thtml = tpage.read().decode('gbk') #print(thtml) file_url = re.search('http://file.finance.sina.com.cn/211.154.219.97:9494/.*?PDF',thtml) try: #print(file_url.group(0)) local = './'+sid+'/'+file_url.group(0).split("/")[-1]+'.pdf' #调试用作文件占位 open(local, 'wb').write(b'success') #print(local) #urllib.request.urlretrieve(file_url.group(0),local,None) except: print('PDF失效;'+target_url)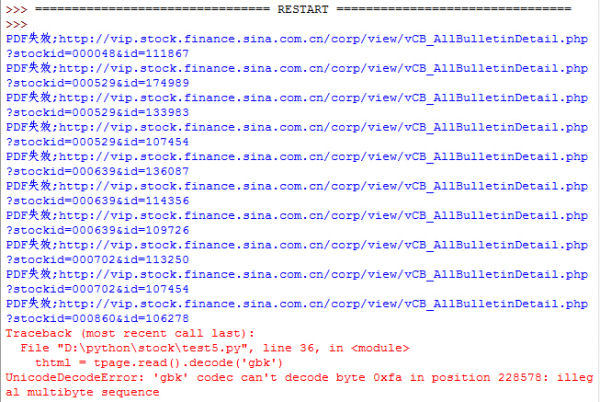
………………又是编码的错误。遇到这种情况也是没办法了。同样的网页别人都能就它不能,还是用try先跳过,最后统一处理吧。为了以防万一我直接把所有涉及页面操作的地方全加了try。
最终代码如下:
import urllib.requestimport reimport osf=open('stock_num.txt')stock = []for line in f.readlines(): #print(line,end = '') line = line.replace('n','') stock.append(line)#print(stock)f.close()#print(stock)for each in stock: url='http://vip.stock.finance.sina.com.cn/corp/go.php/vCB_Bulletin/stockid/'+each+'/page_type/ndbg.phtml' req = urllib.request.Request(url) req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0') page = urllib.request.urlopen(req) try: html = page.read().decode('gbk') target = r'&id=[_0-9_]{6}' target_list = re.findall(target,html) os.mkdir('./'+each) sid = each #print(target_list) for each in target_list: #print(a) #print(each) target_url='http://vip.stock.finance.sina.com.cn/corp/view/vCB_AllBulletinDetail.php?stockid='+sid+each #print(target_url) treq = urllib.request.Request(target_url) treq.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0') tpage = urllib.request.urlopen(treq) try: thtml = tpage.read().decode('gbk') #print(thtml) file_url = re.search('http://file.finance.sina.com.cn/211.154.219.97:9494/.*?PDF',thtml) try: #print(file_url.group(0)) local = './'+sid+'/'+file_url.group(0).split("/")[-1]+'.pdf' #调试用作文件占位 #open(local, 'wb').write(b'success') #print(local) urllib.request.urlretrieve(file_url.group(0),local,None) except: print('PDF失效;'+target_url) except: print('年报下载页面编码错误;'+target_url) except: print('年报列表页面编码错误;'+url)到这里就已经解决了问题~自己试了一下应该是成功的。校园网流量不多了就没有下载全部的PDF而是拿空文件占位跑了一下结果。

最后我手动把控制台的报错信息输入到excel里分列。
PDF失效的情况可以忽视。
年报下载页面编码错误的情况不太多,我测试的时候遇到了13处。可以直接手动解决。
PS。
遇到Errno 11001的报错应该是爬虫被拒绝了。等一会儿重新打开就好。
一次性的解决办法应该是完善headers和加代理。这次的工作量不大,遇到无法访问的情况也不多,就没有写。

To-dos:
- 还是流水式的写法……自己还是不大会模块化的实现
- 要学着用requests代替urllib.request,学着使用BeautifulSoup
- 报错信息或许可以自动写入excel……然后程序自动处理报错的那些页面……编码问题最烦人了
- 自己没怎么遇到网络问题大概是因为数据量小…除了刚开始测试下载了整个PDF后面都是在拿空文件占位,数据量大容易被服务器封掉,还是要完善headers和proxyList
参考答案如下:
scrapy配合chrome或者firefox分分钟的事
查看评论 回复
