2019 年对于 Arm 来说是振奋人心的一年,在移动端这家公司仍像往常一样如日中天,而在云服务领域,越来越多公司(如亚马逊、华为等)推出了基于 Arm 架构的服务器芯片,而英伟达也已宣布旗下 GPU 可以配合 ARM 处理器进行深度学习加速。
但正如我们所知,Arm 芯片仍有其不足之处:过去几年中,Arm 的移动端 Cortex 内核一直活在苹果高度定制版 CPU 微体系结构的阴影之下,苹果的「黑科技」总是有办法能展现超出人们预期的能力——即使前年的 A12 单核性能也比骁龙 865 高出 15%(当然,多核性能是后者更好了)。这些差距尽管有技术上的原因,当然也有 Arm 在商业上的考量。
不过这一切在下一代 Arm 芯片上看起来要有变化了,在昨天 Arm 2020 TechDay 活动上,人们期待已久的 Cortex-A78 确实终于面世了,而且这次 Arm 还放了一个大招:推出了 Cortex-X1 CPU 作为该公司的新旗舰架构。
此举不仅令人惊讶,也标志着 Arm 向多种设备妥协的理念正在产生变化。 全新 Cortex-A78:功耗效率翻倍
首先我们还要从 Cortex-A78 来看起。两年前 Arm 提出的未来路线图就透露了代号为 Hercules 的架构,它就是 A78 的前身,其代表了最新 Austin 系列 CPU 微体系结构的第三次迭代,这一系列自 A76 开始。
全新 Cortex-A78 很大程度上还是按照 Arm 传统的设计理念来打造的,它严格遵循着性能、功率和面积之间的平衡(PPA)来设计。在保持功耗不爆炸的前提上,A78 有了 20% 的性能提升——这是结合微体系结构改进和全新的 5 纳米制程工艺带来的改进。 Cortex-A78:遵循平衡设计
新一代 Cortex-A78 在 Arm 的路线图上已经存在了几年,一直被认为会是 Austin 系列中最小的一代微体系结构升级。作为 Arm 的 Austin 核心设计的第三次迭代,A78 遵循了 Arm 在 Cortex-A76 和 A77 上实现的 25-30%的 IPC 改进。
由于 X1 CPU 架构的出现,A78 这次可以更加专注于效率的提升,我们自然地看到 Arm 的目标在于合理地提升性能。它仍然是 Arm 8.2 CPU,与 Cortex-A55 CPU 分享 ISA 兼容性。在 Arm 给出的设计模板上,我们可以看到每个 DSU(DynamIQ Shared Unit)可有 4 个核心,L3 缓存最多可扩展到 4MB。
在核心的很多地方我们都可以找到微架构改进的痕迹。在前端最大的变化是分支预测器,它现在能够在每个周期处理最多两个分支,去年的 Cortex-A77 本质上每个周期只能解决一个。在 L1I 缓存方面,现在我们可以看到 Arm 提供了 32KB 的实现选项,它可以使客户进一步缩小内核面积,对性能的影响不大,但效率却有不少提升。
在中核与执行流水线中,大部分工作都在于改善设计的面积和功率效率。我们看到了更多的指令融合案例,这不仅有助于提高内核性能,也还提高了电源效率,因为在相同的工作量下,它消耗的资源越来越少,能耗也变得更小。
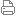
总体而言,如果单独发布 Cortex-A78,恐怕人们会感到有些失望,因为我们看到的是大量减少结构尺寸、牺牲少许性能提高效率的设计。考虑到 X1 的出现,这自然是有道理的。 性能与功耗的完美结合
精准定义期待的性能,新的 Cortex-A78 应达到的功率和 X1 内核的面积增益。






 发表于 2020-5-27 20:24:14
发表于 2020-5-27 20:24:14
 收藏
收藏