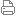
于是乎 Apple 提出了自己 ARM 版 Mac 新品的结构图,也就是上图。这次芯片换代, Apple 不仅处理掉了第三方的 CPU,且一并处理掉了第三方的 GPU。仔细观察,你会发现这个片上系统除了 CPU 与 GPU 之外,还包含了许多其它的重要模块。首先 T2 不需要在单独放一颗芯片,将安全模块整合进来即可。接着将高性能的显卡整合进来,高性能的统一访问存储整合进来,满足未来需求的神经网络运算模块整合进来。加密加速模块,视频独立硬解模块,内核保护模块,能耗管理模块,HDR 显示支持模块,视频播放模块全给它放进来。这样的规划是之前的因特尔架构下不可能做到的,即不方便加新的硬件,也不可能做硬件间整合。
那么很多人好奇的为什么 FCPX 可以在 A12Z 上跑三路 4K ProRes 视频,正是因为这里负责视频解码的不是 CPU,也不是 GPU,而是 A 系列芯片里独立的视频编码硬件模块。这个模块和 Apple 放在自己 Mac Pro 上的那个用于 ProRes RAW 加速的 Afterburner 卡设计思路类似。
说完了视频解码,你也许会问这个 A 系列芯片里的 CPU 和传统的 x86 CPU 有什么区别?在传统的多核心处理器中,各个处理器的能力是非常接近的。比如英特尔的四核处理器,可以类比成四个能力相当的克隆人。
而在 ARM 芯片中,设计则有很大区别,ARM 架构中的 CPU 分为性能核心和低功耗核心。这里注重能耗指的并不是为了省电而牺牲性能,而是指需要多少性能付出多少劳动,不要杀鸡用牛刀 (空费电)。
说完了 ARM 在 CPU 运算上的区别,我们来聊聊内容显示。最近新闻中一个常见的误解便是把 Rosetta 翻译后的图像效能也当作被折损的效能,其实不然。罗赛塔翻译器本质上来说是个指令集翻译器,在把 x86 指令集的内容翻译到精简指令集时确实有性能折损,但这个折损和图形显示没有一点关系。
当计算机需要 GPU 来处理图形运算时,我们需要用一种特殊的语言来和显卡沟通,这个语言我们叫做图形框架。大家所熟知的图形框架可能有微软的 DirectX,开源的 OpenGL 和 Apple 自家的 Metal 框架都属其中。即便是被翻译后的应用,也会直接调用 Metal 指令对显卡做出访问,因此没有图形性能折损。 Apple 过去五年始终喊着让开发者尽快使用跨平台 Metal 框架,除平台统一性考量外,便也在为这次转型做准备。
上文中我们说完了 ARM 的芯片核心,接下来我们将目光放在软件上。要了解其性能表现,我们需要对它们的运行方式做个区分。在 ARM 版的 Mac 上,软件有如下运作方式:
所有 Apple 自家应用,包括系统本身以 ARM 原生模式运行,无任何性能折损;所有 iOS 和 iPadOS 应用,以 ARM 原生模式运行,无任何性能折损;所有虚拟机应用,运行在 Big Sur 提供的虚拟机环境下;所有 Catalyst 应用,需重新编译为 Universal 应用,无任何性能折损;
所有 32 位 x86 应用,已在三年前被 Apple 淘汰,无法运行;所有 64 位 x86 应用,若以应用商店分发,则下载的便是已翻译版本;所有 64 位 x86 应用,若在网络上下载安装,则在安装时翻译;所有 64 位 x86 应用,若以拖拽形式安装,则在首次运行时翻译。
WWDC 展示的古墓丽影虽是翻译应用,但它的性能主要由 GPU 体现。翻译后游戏的渲染仍使用 Metal 指令,因此性能本没有折损,反馈到帧数上便是高帧数运行。而剪辑 4K 用的是 A 系列芯片中的视频硬解码模块,专长于处理 ProRes 视频,所以可以同时编辑多路视频。
可能你会觉得有点反常识,但这次 ARM 的切换与英特尔挤牙膏太久并无直接关联。Mac 这次的芯片变革需要撑得起未来十年,其最优解便是将专精芯片以最优工艺的整合在 Soc 中。






 发表于 2020-8-4 15:15:43
发表于 2020-8-4 15:15:43
 收藏
收藏