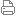
用户态线程与内核态线程多对一 用户态和内核态映射之二--一对一
让每个用户态线程分配一个单独的内核态线程,每个用户态线程通过系统调用创建一个绑定的内核线程,这种模型能够并发执行,充分利用多核的优势,出名的 Windows NT 即采用这种模型,但是如果线程比较多,对内核的压力就太大
用户态线程与内核态线程一对一 用户态和内核态映射之三--多对多
即 n 个用户态线程对应 m 个内核态线程。m 通常小于等于 n,m 通常设置为核数,这种多对多的关系减少了内核线程且完成了并发,Linux 即采用的这种模型
用户态线程与内核态线程多对一用户态线程与内核态线程多对多
一台计算机会启动很多进程,其数量当然是大于 CPU 数量,只好让 CPU 轮流的分配给它们,让我们产生了多任务同时执行的错觉,那有没有想过这些任务执行之前,CPU 都会干啥?
CPU 既然要执行它,势必会去了解从哪里加载它,又从哪里开始运行,也就是说,需要系统提前将它们设置好 CPU 寄存器和程序计数器。
你眼中的寄存器和程序计数器是什么?
它虽小不过威力却很大,速度很快的内存。而程序计数器用来记录正在执行指令的位置,这些 CPU 需要依赖的环境即 CPU 的上下文。上下文知道了,那么 CPU 的切换是不是就很好理解。
将前一个任务的 CPU 上下文保存下来,加载新任务的上下文到寄存器和程序计数器中,然后跳转到程序计数器所指向的位置。根据任务的不同又分为进程的上下文和线程的上下文。
进程的上下文
进程在用户空间运行的时候叫做用户态,陷入到内核空间叫做进程的内核态,如果用户态的进程想转变到内核态,则可以通过系统调用的方式完成。进程由内核调度,进程的切换发生在内核态
进程的上下文包含哪些数据?
既然进程的切换发生在内核态,那么进程的上下文不仅仅包括虚拟内存,栈,全局变量等用户空间资源,还包括了内核堆栈,寄存器等内核空间的状态
这里的保存上下文和恢复上下文也不是说免费的,需要内核在 CPU 上运行才能完成
描述信息包含进程的唯一识别号,进程的名称以及用户等
除了给进程安排一张表以外,给线程也安排了一张表,这就是线程表。线程表也包含了一个 ID,这 ID 叫做 ThreadID,同时也会记录自己在不同阶段的状态,比如阻塞,运行,就绪。由于多个线程会共用 CPU 且需要不停的切换,所以需要记录程序计数器和寄存器的值。
说到了用户级的线程和内核级的线程,两者又是怎么个亲密关系 两者映射的关系如何去表示?
可以想像在内核中有一个线程池,给予用户空间使用,每次用户级线程把程序计数器等传递过去,执行结束后,内核线程不销毁,等待下一个任务,从这里可以看出创建进程开销大、成本高;创建线程开销小,成本低。 这么多进程难道共用内存?
操作系统太多的进程,为了让他们各司其职,互不干扰,考虑为他们分配完全隔离的内存区域,即使程序内部读取相同的内存地址,但实际上他们的物理地址也不一样。就仿佛我在 X 座的 501 和你在 Y 座的501一样却不是一个房子,这就是地址空间
所以在正常的情况下 A 进程不能访问 B 进程的内存,除非你植入一个木马,恶意操作 B 进程的内存或者通过我们后面说的进程间通信的方式进行访问 那进程线程怎么切换的呢?
操作系统的大量进程需要来回的切换,保持有借有还再借不难的传统美德,每次切换之前需要先记录下当前寄存器值的内存地址,方便下次回到原位置继续执行。恢复执行的时候就从内存中读取,然后恢复状态执行即可
进程切换
为了详细的让大家理解这个过程,我将其拆分为下面几个步骤






 发表于 2021-3-28 17:55:12
发表于 2021-3-28 17:55:12
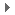
 收藏
收藏